Job mode¶
SQLFlow Job mode is dedicated for handling large amounts of SQL Scripts or directly connecting to the target database server for the data linenage analysis. Config parameters for the analysis should be given when creating a new SQLFlow Job and the parameters cannot be changed once submitted.
Job type¶
There are two job types:
- Simple Job (Standard Job)
- Regular Job (Incremental Job)
 (1) (1) (1) (1) (1) (1) (1).png)
Both Simple Job and Regular Job support reading large amounts of SQL files or analysis through DB directly. There are some differences between Simple Job and Regular Job.
Simple Job¶
- Possible to add some configs. Once submitted, the configs cannot be changed
- Result will be persisted in the file system as files
- Possible to do the Left Most analysis (Left Most: given a->b->c, show a->c )
- Data lineage result is saved in dataflow.xml file
1 2 3 4 5 6 7 8 9 10 11 | |
Configurable Parameter: The parameters which can be set before the job creation. There's no way to change such parameters once the job is created. You have to create a new job with the new parameter value if needed.
Regular Job¶
- Unable to set any data lineage configs
- Support table level lineage
- Result will be in database
- Support if incremental, possible to anaylze SQL scripts or database in batches
- Possible to do the Left Most analysis (Left Most: given a->b->c, show a->c )
- Possible to do the Upstream and Downstream analysis (given a->b->c, Upstream: a->b, Downstream: b->c)
- Data lineage result is saved in database
1 2 3 4 5 6 7 8 9 10 11 12 | |
Configurable Parameter: The parameters which can be set before the job creation. There's no way to change such parameters once the job is created. You have to create a new job with the new parameter value if needed.
Job parameters and UI Settings parameters¶
Some of the above parameters cover the parameters in UI Settings section
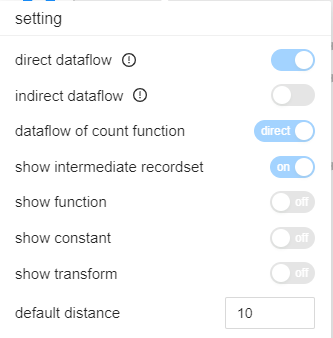
showConstantTable has the same effect as show constant
ignoreFunction has the same effect as show function
ignoreRecordSet has the same effect as show intermediate recordset
showTransform has the same effect as show transform
dataflowOfAggregateFunction has the similar effect as dataflow of count function
Summary Result¶
When using SQLFlow Front UI, all data lineage will be returned if the number of relationship is less than 1,000. However, only database, schema, table, view data and the number of above DB units will be returned if the number is more than 1,000. No relationship data will be returned in the case and this is called Summary result.
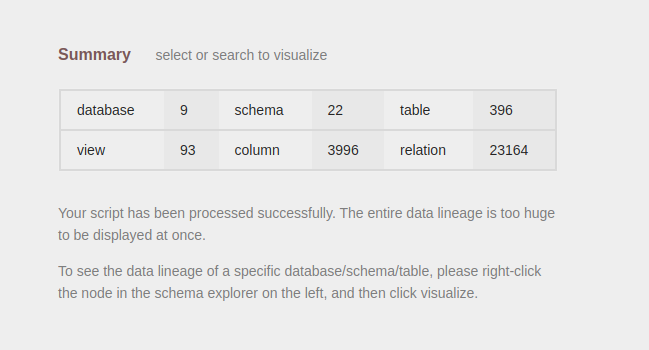
User can request specific database, schema, table or view but result will be in Summary mode if the result number is more than 1,000.
There's a performance limitation in the frontend page rendering and moreover the graph will be complex to understand so we impose a restriction on the UI endpoint (/sqlflow/generation/sqlflow/graph). However, request to the /sqlflow/generation/sqlflow for SQLFLow Rest Api doesn't have such limitation.