Job Sources¶
Job source can be from one of the following sources:
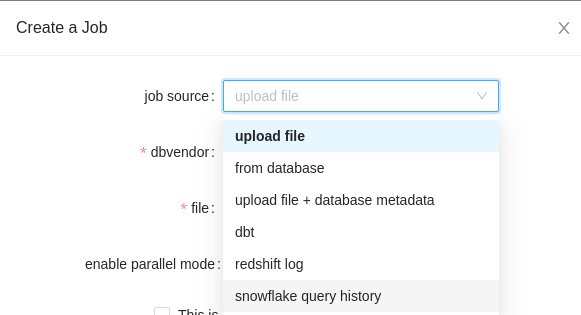
Upload file¶
upload file: The data lineage will be generated from your sql meta file(DDL file for an example). You can upload multiple sql files by compressing them into one zip file and upload the zip file. You can also upload the DDL file or the json result generated by Ingester in the zip file to resolve the ambiguities(Check here for more details about the ambiguity in the data lineage).
Check our Ingester tool if you would like to take this approach but don't have any compatible sql metadata file.
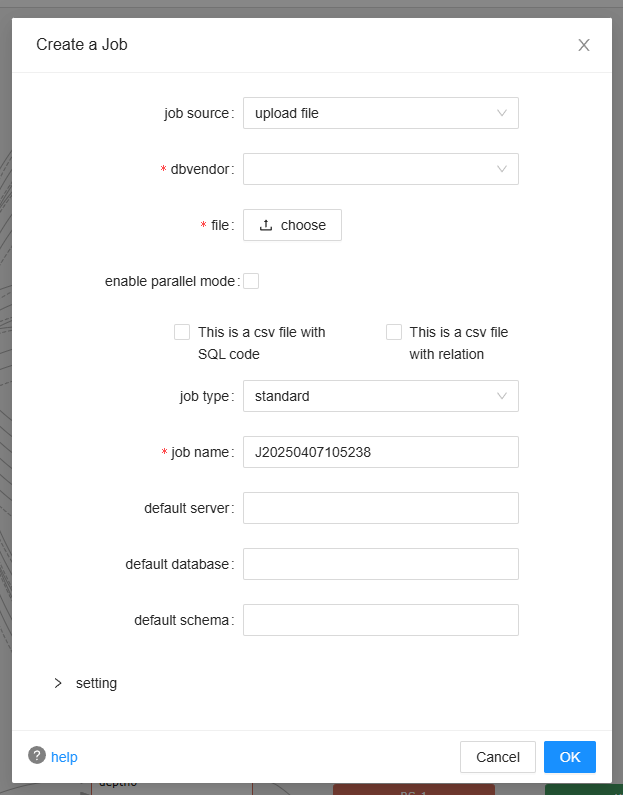
Read more about the setting section here.
Note: The uploaded file must be less than 200MB.
From database¶
from database: SQLFLow is able to directly read information from the database server and analyze your data lineage. Connection information is required in this mode.
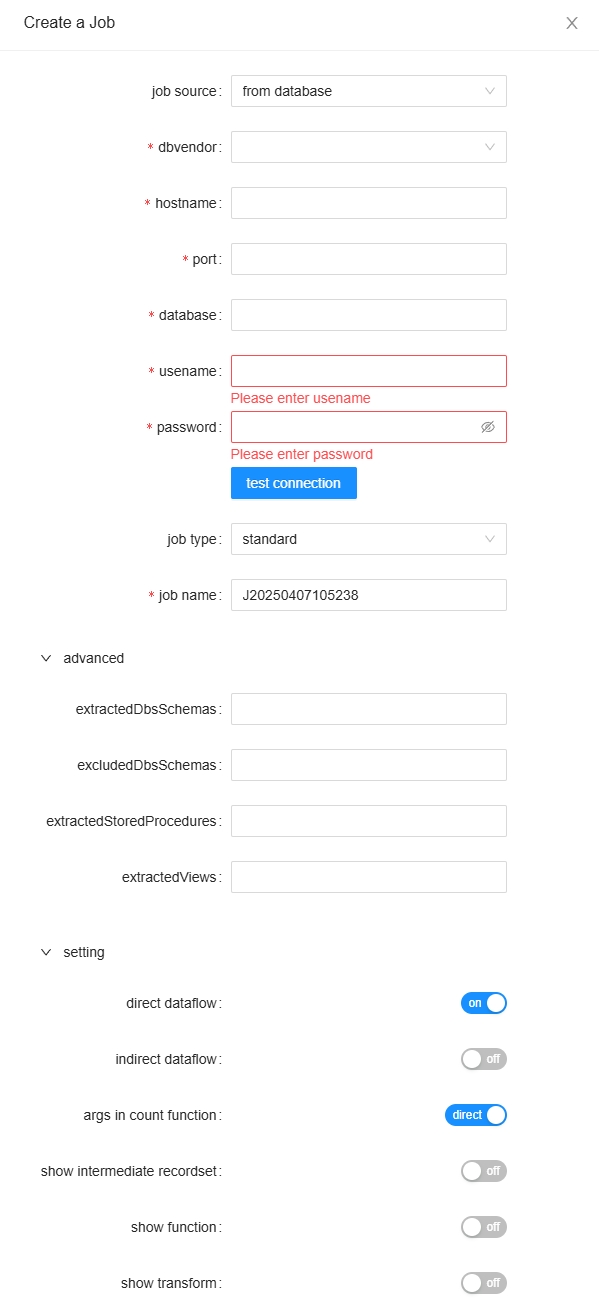
Read more about the setting section here.
The schemas should be in full path. In Oracle, schema name is same as DB name so only give schema name is good for Oracle. Read more about the advanced section here.
Upload file + database metadata¶
upload file + database metadata: Use the above two methods to create the Job together. The database metadata will be used to resolve the ambiguities in the uploaded file (Check here for more details about the ambiguity in the data lineage). Queries in the database metadata will not be analyzed because the main purpose of using database metadata is eliminating the ambiguity in this scenario.
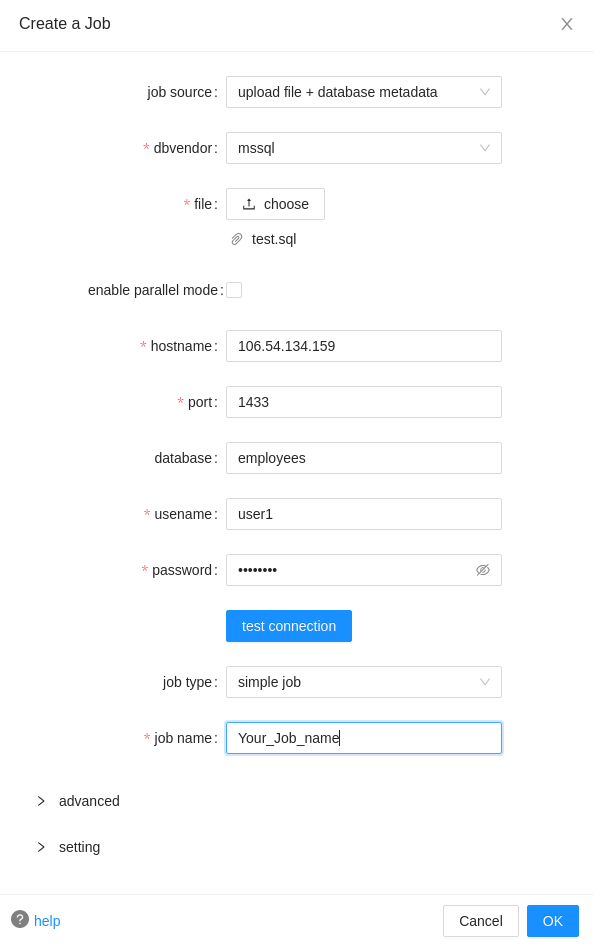
Read more about the setting section here.
Read more about the advanced section here.
Note: The uploaded file must be less than 200MB
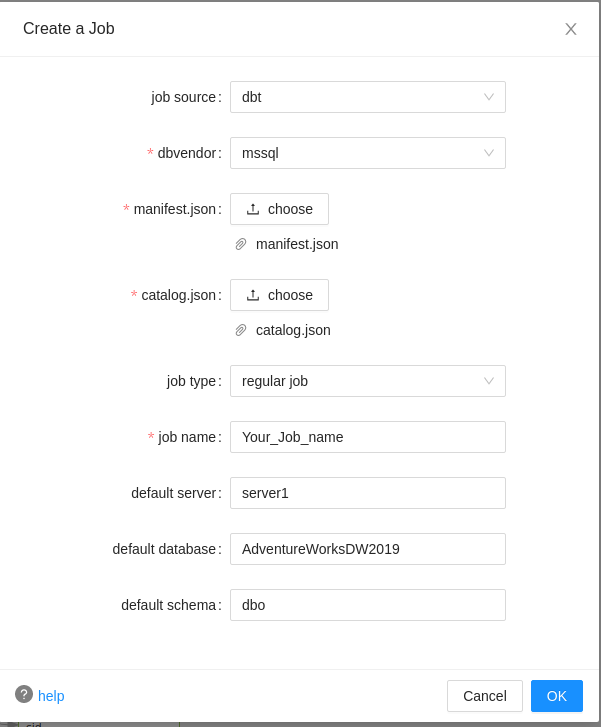
Dbt¶
dbt: Read data lineage from your dbt. dbt is an ETL tool for data transformation. Data lineage can be retrieved from dbt data.
The manifest.json and the catalog.json will be required. Both files can be found under the target folder of your dbt tranformation project.
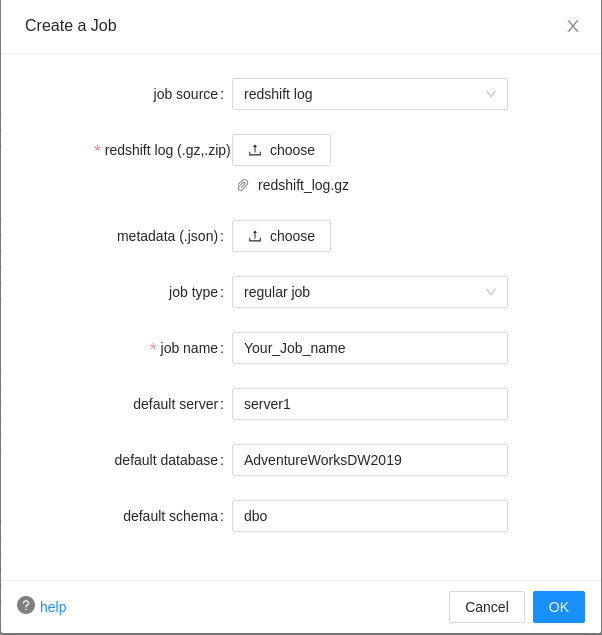
RedShift log¶
redshift log: Read from your redshift log. Amazon Redshift is a cloud data warehouse. You should give your redshift log and the file should be in .gz or .zip format. You may compress multiple .gz files into one .zip file and folder nesting structure is supported in the .zip file. You can also give your database's metadata.json as a supplementary source.
Snowflake query history¶
snowflake query history: Read from your snowflake query history. Snowflake is a SaaS platform database. We can get the data lineage from your snowflake query history. However, the query history continues to grow with the use of the database so it would be better to check your query history data regularly. You can use enableQueryHistory flag to choose werther fetch from the query history.
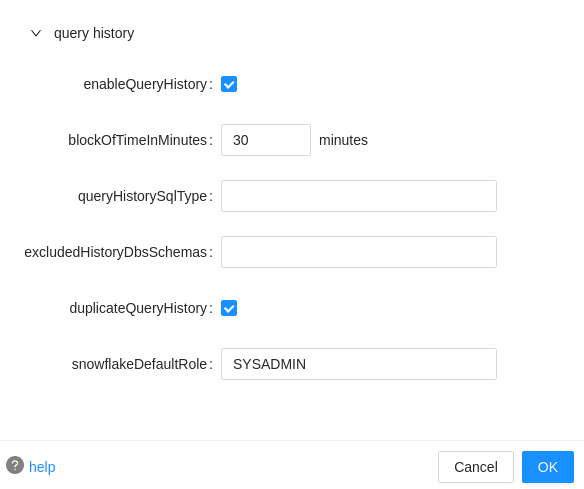
enableQueryHistory: Fetch SQL queries from the query history if set to true.
blockOfTimeInMinutes: When enableQueryHistoryis set to true, the interval at which the SQL query was extracted in the query History. Default is 30 mins.
queryHistorySqlType: Specify what's kind of SQL statements need to be sent to the SQLFlow for furhter processing after fetch the queries from the Snowflake query history. If queryHistorySqlType is specified, will only pickup those SQL statement type and send it the SQLFlow for furhter processing. This can be useful when you only need to discover lineage from a specific type of SQL statements. If queryHistorySqlType is empty, all queries fetched from the query history will be sent to the SQLFlow server.
excludedHistoryDbsSchemas: List of databases and schemas to exclude from extraction, separated by commas database1.schema1,database2.
duplicateQueryHistory: Whether filter out the duplicate query history.
snowflakeDefaultRole: The role when connecting the snowflake database. You must define a role that has access to the SNOWFLAKE database and assign WAREHOUSE permission to this role.