Relations generated by SQLFlow¶
The main relation type in dataflow¶
- column to column dataflow, the data of target column is coming from the source column(fdd).
- column to resultset(mainly select list), the number of row in the resultset is impacted by the source column(fdr).
- resultset to resultset, the number of row in a source table in the from clause impact the number of row in the target select list.(fdr)
Analyze dataflow in the different SQL elements - part 1¶
- select list
- where clause
- function (case expression)
- group by(aggregate function)
- from clause
- handle of select * (Not finished yet)
1. select list
1 2 | |
the data of target column "eName" comes from scott.emp.empName, so we have a dataflow relation like this:
1 | |
the result generated by the select list called: resultset likes a virtual table includes columns and rows.
2. where clause
1 2 3 | |
The total number of row in the select list is impacted by the value of column sal in the where clause. So we have a dataflow relation like this:
1 | |
As you can see, we introduced a new pseudo column: PseudoRows to represents the number of rows in the resultset.
3. function
During the dataflow analyzing, function plays a key role. It accepts arguments which usually is column and generate resultset which maybe a scalar value or a set value.
1 | |
The relation of the round function in the above SQL :
1 | |
4. group by and aggregate function
1 2 3 4 | |
4.1
since SUM() is an aggregate function, so deptno column in the group by clause will be treated as an implict argument of the SUM() function. However, deptno column doesn't directly contribute the value to the SUM() function as column SAL does, So, the relation type is fdr:
1 | |
the columns in the having clause have the same relation as the columns in the group by clause as mentioned above.
4.2
The value of SUM() function also effected by the total rows of the table scott.emp, so, there is a relation like this:
1 | |
The above rules apply to all aggregation functions, such as the count() function in the SQL.
5. From clause
If the resultset of a subquery or CTE is used in the from clause of the upper-level statement, then the impact of the lower level resultset will be transferred to the upper-level.
1 2 3 4 5 6 7 8 9 10 11 | |
In the CTE, there is an impact relation:
1 | |
Since cteReports is used in the from clause of the upper-level statement, then the impact will carry on like this:
1 | |
If we choose to ignore the intermediate resultset, the end to end dataflow is :
1 | |
Handle the dataflow chain¶
Every relation in the SQL is picked up by the tool, and connected together to show the whole dataflow chain. Sometimes, we only need to see the end to end relation and ignore all the intermediate relations.
If we need to convert a fully chained dataflow to an end to end dataflow, we may consider the following rules:
-
A single dataflow chain with the mixed relation types: fdd and fdr.
1A -> fdd -> B -> fdr -> C -> fdd -> Dthe rule is: if any
fdrrelation appears in the chain, the relation fromA -> Dwill be consider as type offdr, otherwise, the final relation isfddfor the end to end relation ofA -> D. 2. If there are multiple chains fromA -> D1 2 3
A -> fdd -> B1 -> fdr -> C1 -> fdd -> D A -> fdd -> B2 -> fdr -> C1 -> fdd -> D A -> fdd -> B3 -> fdd -> C3 -> fdd -> DThe final relation should choose the
fddchain if any.
Analyze dataflow in the different SQL elements - part 2¶
1. case expression
1 2 3 4 5 6 7 8 | |
During the analyzing of dataflow, case expression is treated as a function. The column used inside the case expression will be treated like the arguments of a function. So for the above SQL, the following relation is discovered:
1 2 | |
2. join condition
Columns in the join condition also effect the number of row in the resultset of the select list just like column in the where clause do. So, the following relation will be discoverd in the above SQL.
1 2 | |
3. create view
1 2 3 4 | |
From this query, you will see how the column sal in where clause impact the number of rows in the top level view vEmp.
1 | |
So, from an end to end point of view, there will be a fdr relation between column sal and view vEmp like this:
1 | |
4. rename/swap table
1 | |
We also use PseudoRows to represent the relation when rename a table, the relation type is fdd.
1 | |
5. create external table (snowflake)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
The data of the external table exttable_part comes from the stage: exttable_part_stage
1 | |
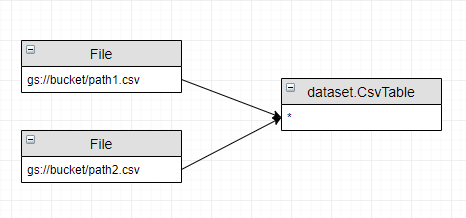
6. create external table (bigquery)
1 2 3 4 | |
The data of the external table dataset.CsvTable comes from the csv file: gs://bucket/path1.csv, gs://bucket/path2.csv
1 2 | |
7. build data lineage for the foreign key in the create table statement.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
The data flow is:
1 2 | |
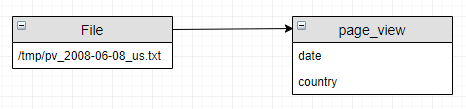
8, Hive load data
1 | |
The data flow is:
1 | |
9, Hive INSERT OVERWRITE [LOCAL] DIRECTORY
1 2 3 | |
The data flow is:
1 | |
The meaning of the letter in fdd, fdr¶
The meaning of the letter in fdd, fdr. f: dataflow, d: data value, r: record set.
The first letter is always f,the second letter represents the source column,the third letter represents the target column, the fourth is reserved.
- fdd: data of the source column will be used in the target column
- fdr: data of the source column will impact the number of the resultset in the select list, or will impact the result value of an anggreate function.